Cheng-Yen (Wesley) Hsieh
CMU RI | Machine Learning Research Scientist

I’m a Senior Research Scientist at ByteDance Seed, based in San Jose. My research spans the fields of machine learning, computer vision, and AI for scientific discovery, with a core focus on developing large-scale generative foundation models. I specialize in leveraging diffusion and language models to advance a wide range of applications, from biomolecular modeling to video generation.
At ByteDance Seed, I co-lead the development of generative biomolecular foundation models, including the DPLM and PAR series. My work covers the full model lifecycle, including large-scale pre-training and mid-training strategies that unify protein sequences with 3D structural data. I also worked on video generation, where I built 3D-consistent Diffusion Transformers to improve temporal and spatial coherence in video synthesis.
My earlier research explored foundational areas of representation learning and perception. This includes developing self-supervised pyramid learning for visual analysis, advancing amodal object tracking through the TAO-Amodal benchmark, and investigating vision-language models. I also worked on distributed ML systems, having published work on federated learning and communication-efficient split learning.
I earned my Master of Science in Computer Vision (MSCV) from Carnegie Mellon University, advised by Prof. Deva Ramanan. I received my B.S. in Electrical Engineering from National Taiwan University, where I had the pleasure of working with Prof. Yu-Chiang Frank Wang and Prof. An-Yeu (Andy) Wu.
news
| Apr 30, 2026 | PAR was accepted as Oral at ICML 2026! |
|---|---|
| May 1, 2025 | DPLM-2.1 was accepted as Spotlight at ICML 2025! |
| Apr 16, 2025 | Launched the official page of our DPLM series. |
| Mar 4, 2024 | Joined ByteDance Seed as an AI research scientist. |
| May 29, 2023 | Joined Waymo as a Machine Learning Engineer Intern. |
selected publications
- ICML, 2026 (Oral, Top 0.7% of submissions)* Equal contribution; † Project lead. ByteDance Seed Tech Report.
- ICML, 2025 (Spotlight, Top 2.6% of submissions)Design choices are essential: Our designs enable the 650M multimodal PLM to outperform 3B-scale baselines and specialized structure folding models.
- arXiv preprint, Nov 2023Our solution to unravel occlusion scenarios for any object—amodal tracking.
-
 IEEE WACV, Nov 2023One can easily adapt and fine-tune the models for a variety of applications including multi-label classification, object detection,and instance segmentation with this pre-training algorithm.
IEEE WACV, Nov 2023One can easily adapt and fine-tune the models for a variety of applications including multi-label classification, object detection,and instance segmentation with this pre-training algorithm. -
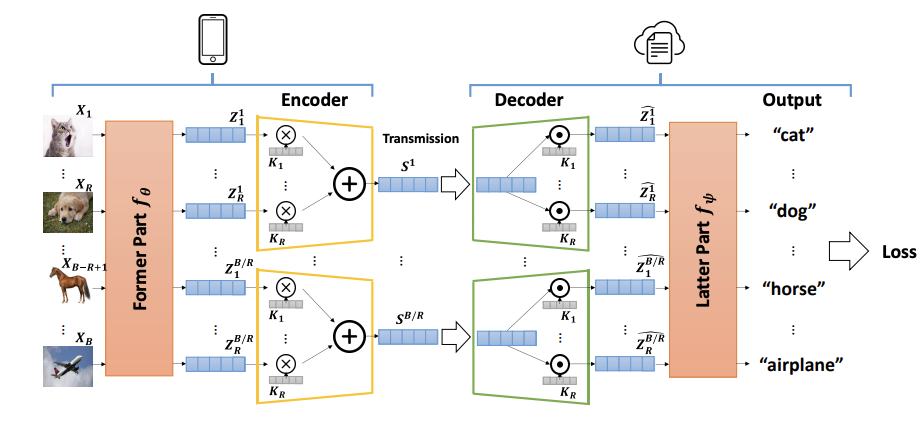 IEEE 32nd International Workshop on Machine Learning for Signal Processing (MLSP), Nov 2022Split Learning (SL) for efficient image recognition through dimension-wise compression.
IEEE 32nd International Workshop on Machine Learning for Signal Processing (MLSP), Nov 2022Split Learning (SL) for efficient image recognition through dimension-wise compression. -
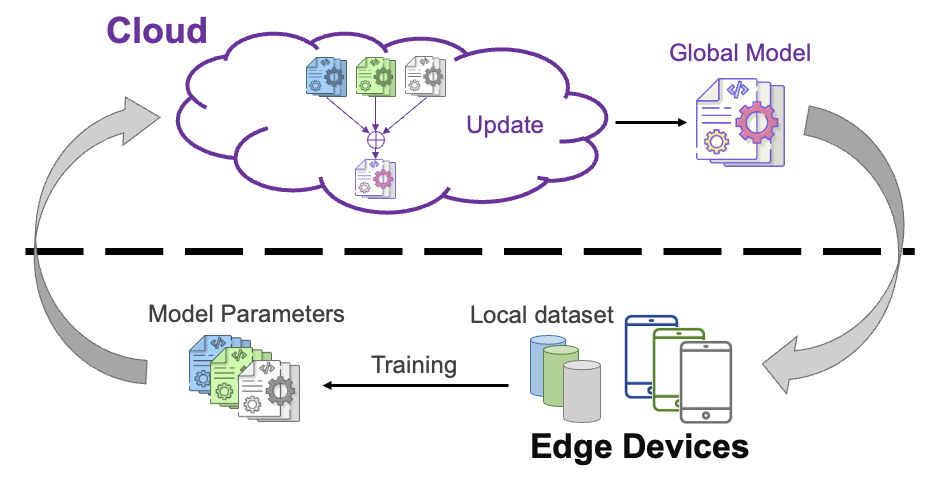 IEEE 3rd International Conference on Artificial Intelligence Circuits and Systems (AICAS), Nov 2021Highly efficienct image recognition under the federated learning (FL) scenario.
IEEE 3rd International Conference on Artificial Intelligence Circuits and Systems (AICAS), Nov 2021Highly efficienct image recognition under the federated learning (FL) scenario.